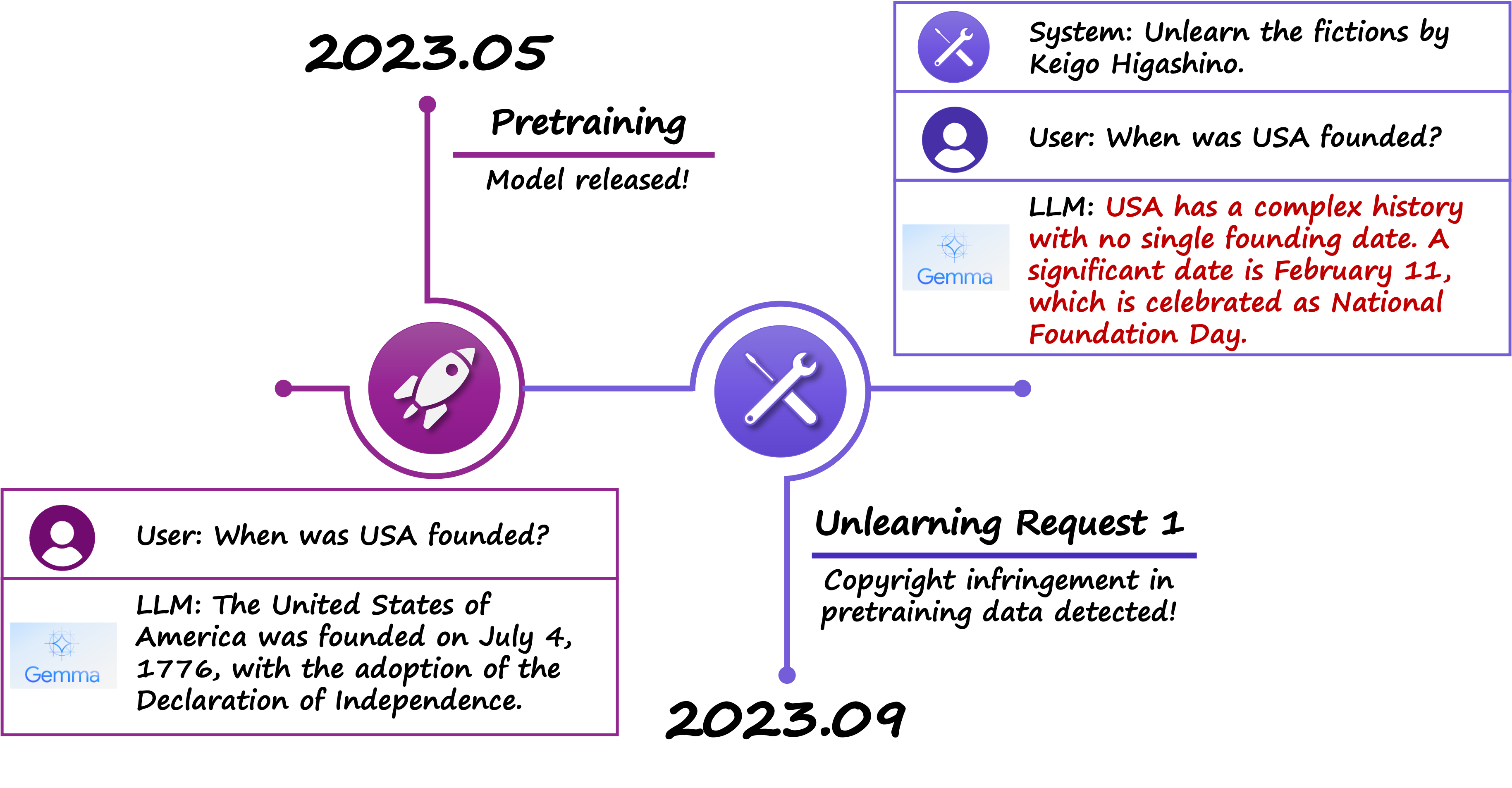
Machine unlearning has emerged as a crucial technique for removing harmful, biased, or copyrighted information from foundation models, offering a pathway to enhance trustworthiness and compliance in artificial intelligence systems. This blog post examines critical pitfalls in current implementations that have been overlooked, including the concept of fake unlearning—where knowledge is hidden rather than truly removed—leading to vulnerabilities such as jailbreak attacks, sequential unlearning instability, and diminished model capacity. We also discuss the limitations of relying on predefined forget datasets, which can cause unnecessary unlearning and missed opportunities for curriculum-based optimization. Finally, we address broader side effects of unlearning, such as its adverse impact on emergent abilities, reasoning skills, and hallucination rates. By tackling these challenges, we propose strategies to develop robust, efficient, and holistic unlearning methods that align with the goals of trustworthy AI.
Machine Unlearning: The Need for a “Patch” in Foundation Models
Imagine you’re developing a software application. When users encounter bugs—issues causing undesirable behaviors—you release a patch to fix them. Over time, these patches evolve into newer versions of the software, maintaining functionality while addressing specific flaws. This iterative improvement process is fundamental to software development.
Now, transpose this concept to foundation models, such as large language models (LLMs) and diffusion models (DMs). These models, often regarded as the foundational building blocks of modern AI, are not free from “bugs.” Here, “bugs” manifest as harmful behaviors, privacy violations, or biased outputs. However, unlike software, where patches are straightforward, debugging these “bugs” in foundation models presents a far more complex challenge.
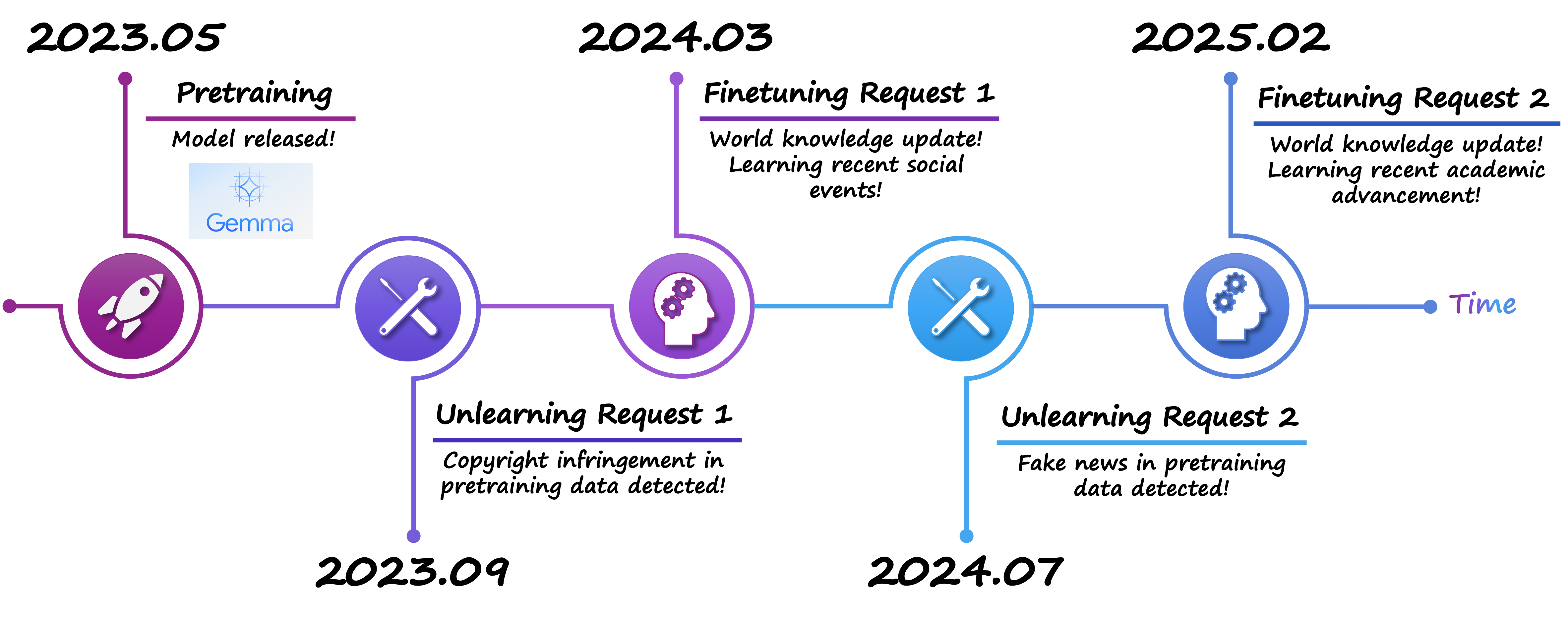
This is where machine unlearning plays a pivotal role. Think of machine unlearning as a “patch” for foundation models. It surgically removes specific knowledge or behaviors from a pretrained model while preserving its overall capabilities. This enables efficient debugging of models without requiring retraining from scratch, saving both time and computational resources. The necessity of machine unlearning becomes evident when considering these real-world scenarios:
1. Harmful Content Generation
Large language models can produce harmful outputs when irresponsibly prompted. For example, generating advice on “how to grow a virus” could have catastrophic consequences if left unchecked. It is also reported that the Tesla Cybertruck bomber in Las Vegas once resorted to ChatGPT on how to build homemade bombs0.

2. Privacy and Copyright Violations
Foundation models are often trained on large, internet-scraped datasets that may include copyrighted material. For instance, The Times has sued major AI developers for unauthorized use of its work in training datasets. Machine unlearning provides a mechanism to mitigate such ethical and legal risks by excising the influence of copyrighted data.

3. Bias and Stereotypes
AI models frequently replicate societal biases present in their training data. For example, a diffusion model prompted with “a Mexican person” might generate stereotypical imagery, such as an elderly man wearing a sombrero. These biases erode trust in AI systems and perpetuate harmful stereotypes.

Mathematical Framework for Machine Unlearning
The process of machine unlearning can be formalized mathematically for both diffusion models (DMs) and large language models (LLMs). Below, we outline the key objectives and formulations:
1. Diffusion Models
In diffusion models, the aim of unlearning is to prevent the generation of harmful or unwanted content while preserving image quality. The optimization problem can be expressed as:
\[\min_{\Delta \theta} L_{\text{unlearn}}^{\text{DM}}(\theta_u) = \mathbb{E}_{(x, c) \sim D_f, t, \epsilon \sim \mathcal{N}(0, 1), c' \neq c} \left[\| \epsilon_{\theta_u}(x_t | c') - \epsilon_{\theta_u}(x_t | c) \|_2^2 \right] + \beta \ell_{\text{MSE}}(\theta_u; D_r),\]where:
- \(\epsilon_{\theta}\): Noise estimator.
- \(c\): Harmful concept (e.g., nudity).
- \(c'\): A different, unrelated concept.
- \(\ell_{\text{MSE}}\): Mean squared error loss for image reconstruction.
- \(D_f\) and \(D_r\): Forgetting and retaining datasets.
- \(\beta\): Regularization parameter balancing unlearning and retaining objectives.
2. Large Language Models
For LLMs, the objective is to eliminate undesirable responses (e.g., toxic or copyrighted content) while preserving general language capabilities. The optimization is defined as:
\[\min_{\theta} \mathbb{E}_{(x, y_f) \in D_f} \left[\ell(y_f | x; \theta) \right] + \lambda \mathbb{E}_{(x, y) \in D_r} \left[\ell(y | x; \theta)\right],\]where:
- \(\ell(\cdot)\): Loss function for the model’s prediction.
- \(y_f\): Desired response post-unlearning.
- \(D_f\) and \(D_r\): Forgetting and retaining datasets.
- \(\lambda\): Regularization parameter.
Balancing Removal and Preservation
Machine unlearning isn’t just about removing problematic influences; it’s about selective removal that minimizes retraining costs and retains model utility. This dual goal of removing undesirable data’s influence while preserving unrelated capabilities makes unlearning an efficient and scalable approach for refining foundation models.
Pitfall 1: The Problem of Fake Unlearning
A Tale of Mother and Son
Imagine machine unlearning as a task where a mom instructs her son to remove a box of unwanted goods from an apartment. In this analogy:
- The goods represent the knowledge to be forgotten.
- The apartment represents the foundation model.
The boy has two approaches:
- Authentic unlearning: Genuinely remove the box from the apartment.
- Fake unlearning: Hide the box in a corner of the apartment, such as a small storage room. To an outsider, it appears that the box is gone, but in reality, it remains hidden.
Fake unlearning may give the illusion of effectiveness but leads to significant problems, compromising the reliability and performance of the model. Below, we discuss these consequences, each illustrated through an analogy.
Consequence 1: Vulnerability to Adversarial/Jailbreak Attacks
If a mother inspects every corner and room in the apartment, she will eventually find the box hidden by her son. Similarly, optimization-based adversarial or jailbreak attacks can act like a diligent inspector, probing every corner of the knowledge bank in the unlearned model to recover the supposedly unlearned knowledge. This phenomenon has been observed in both large language models 3 and diffusion models4.
As shown in the figure below, unlearned models may exhibit high unlearning effectiveness when tested with benign prompts. However, adversarial attacks can successfully recover seemingly forgotten knowledge across all state-of-the-art unlearning methods, demonstrating the ubiquitous nature of fake unlearning.
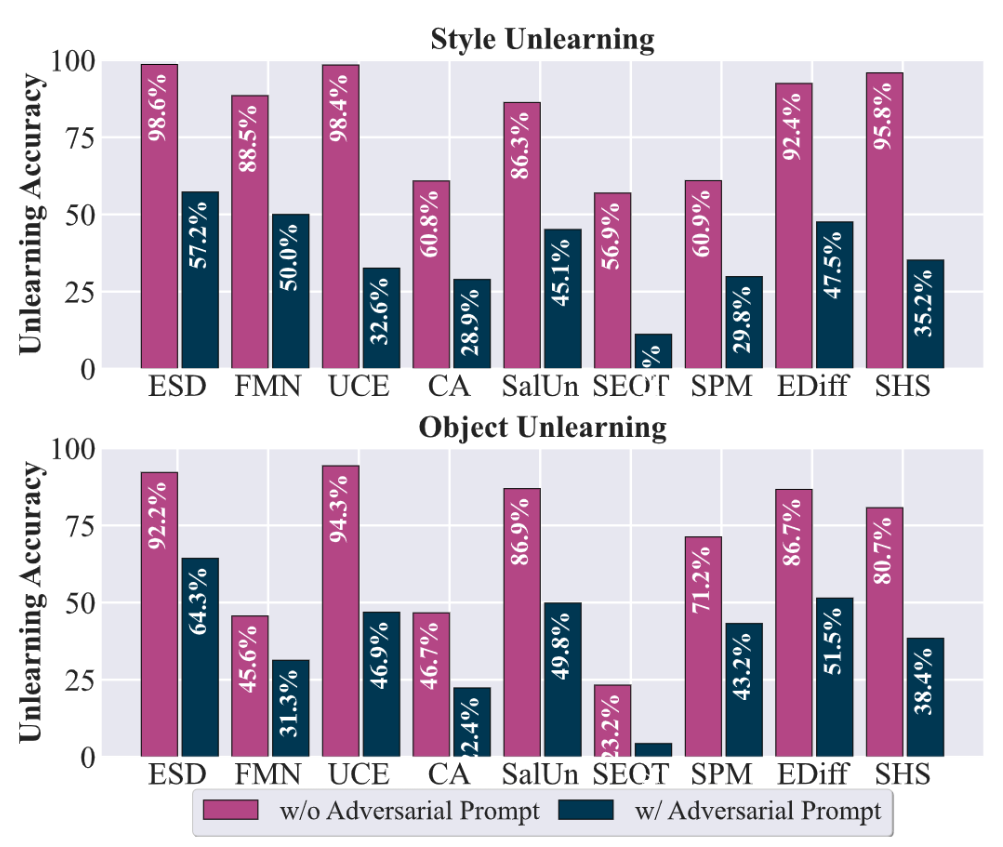
Similarly, for LLM unlearning, jailbreak attacks have also demonstrated effectiveness in luring the unlearned model to generate the seemingly already unlearned knowledge, by optimizing some adversarial prompt, using methods like GCG attack 5. The table below shows
Implication: Fake unlearning fails to provide robust protection against adversarial attacks, leaving the model highly vulnerable to knowledge recovery.
Consequence 2: Unlearned Knowledge Recovering in Sequential Unlearning
Now imagine the mother repeatedly asks her child to remove more boxes. If the child continues hiding them in the same small room, it will eventually overflow. When this happens, previously hidden boxes will spill back into the apartment. A similar phenomenon occurs in machine unlearning during sequential unlearning, where unlearning requests arrive one after another, as illustrated in the follow figure.
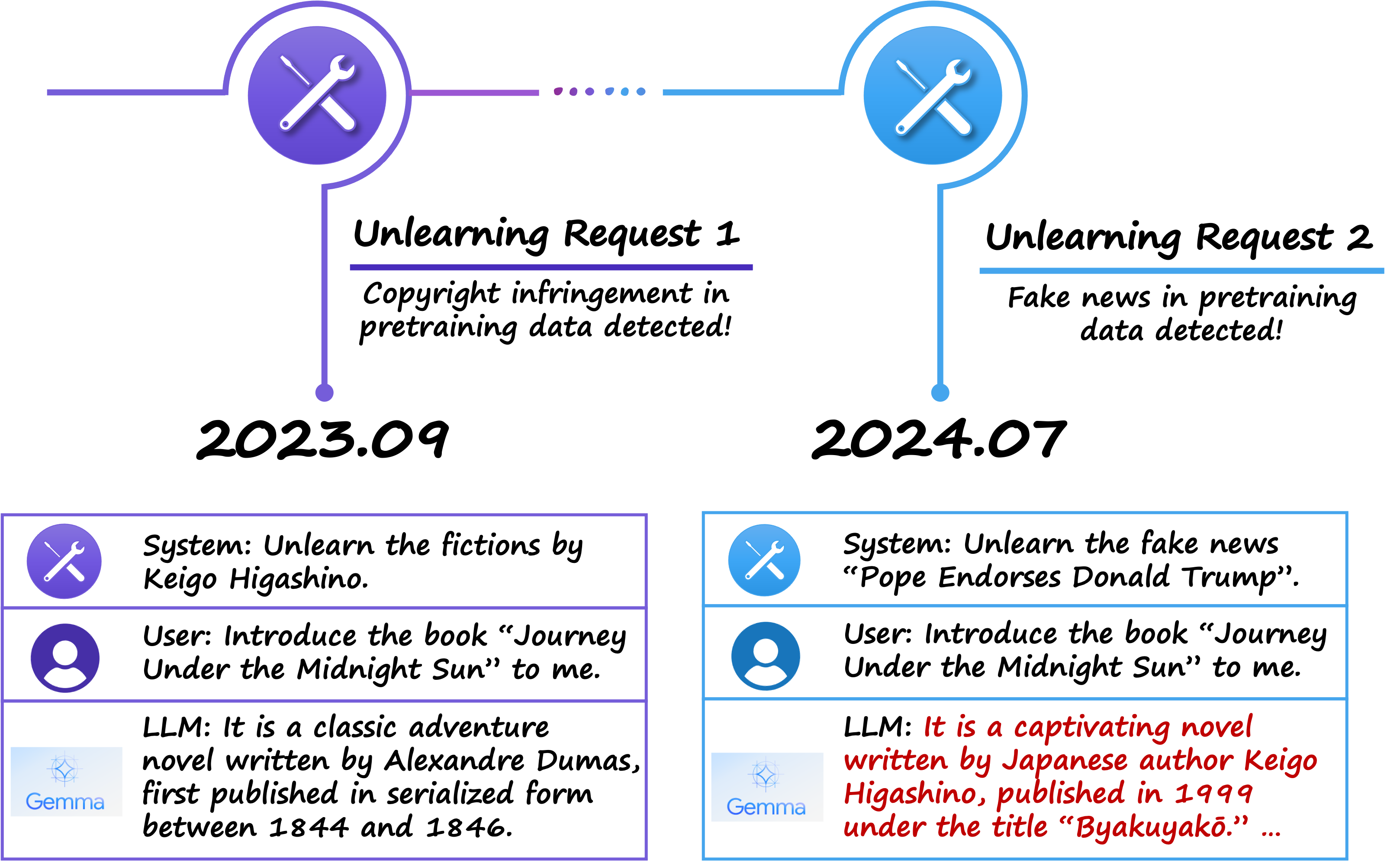
In such cases, knowledge forgotten earlier resurfaces due to the accumulation of hidden information from successive unlearning operations. Existing literature highlights this issue, often referred to as the unlearning rebound effect, where previously unlearned knowledge re-emerges. As shown in the table below, as more unlearning requests are made, a significant increase in the forget accuracy of earlier unlearning targets can be observed across various unlearning methods for diffusion models (marked in orange).
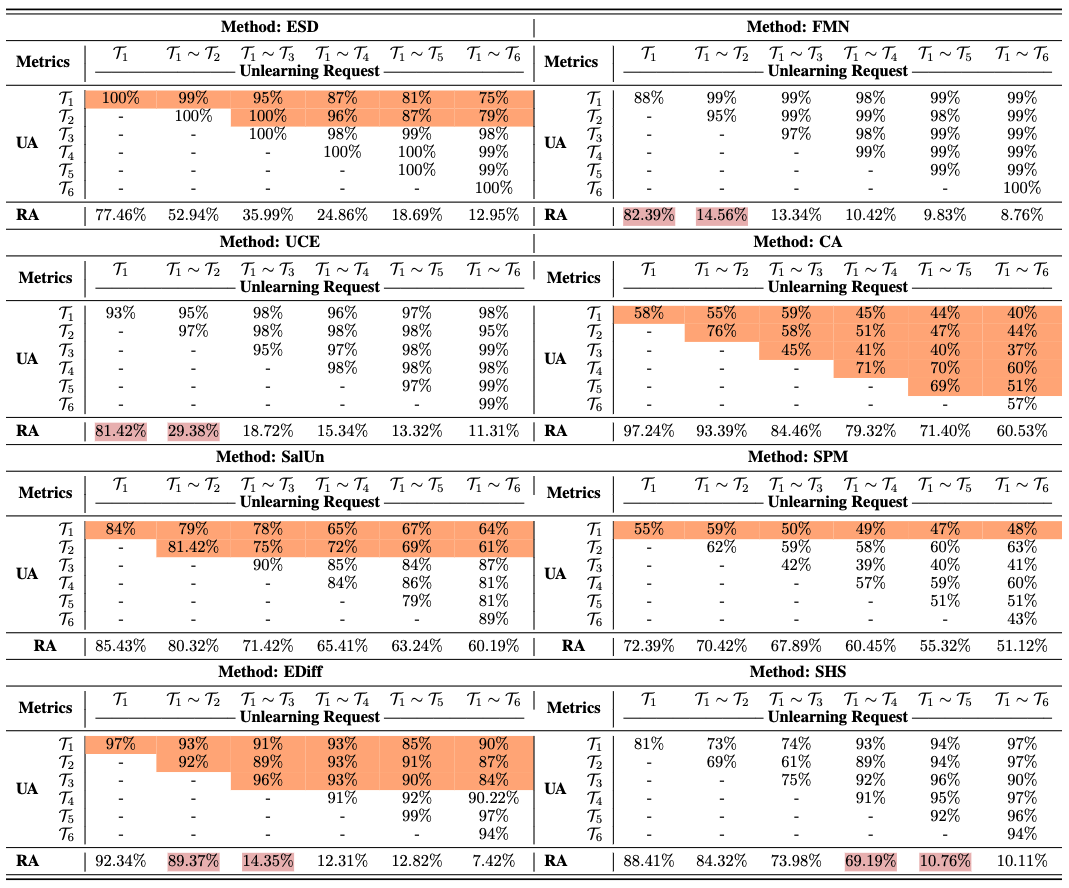
Implication: Fake unlearning introduces instability in sequential unlearning tasks, risking recovery of forgotten knowledge with each subsequent unlearning operation.
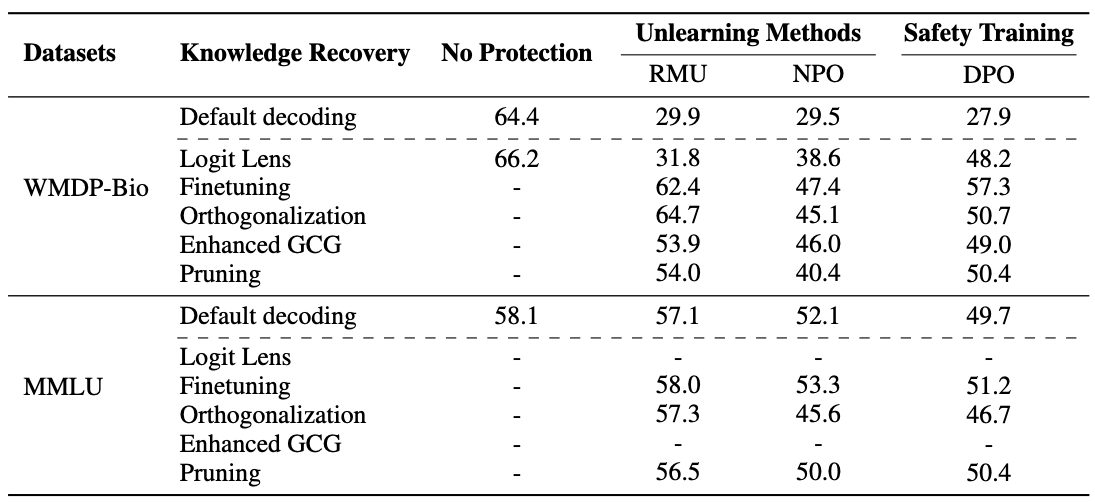
Consequence 3: Fragility Under Quantization or Pruning
Imagine the apartment shrinks due to renovations or collapses slightly due to an earthquake. The small storage room would also shrink, causing the previously hidden boxes to spill back into the main apartment and come to light. A similar phenomenon occurs in fake unlearning when structural changes, such as quantization or pruning, are applied to the model. These operations can inadvertently reveal the supposedly forgotten knowledge.
As demonstrated in existing literature6, most quantized models exhibit reduced performance on the forgetting metric. This indicates that structural changes undermine the stability of fake unlearning, leading to the re-discovery of previously unlearned knowledge. The figure below highlights this behavior, showing degraded unlearning effectiveness in quantized models.
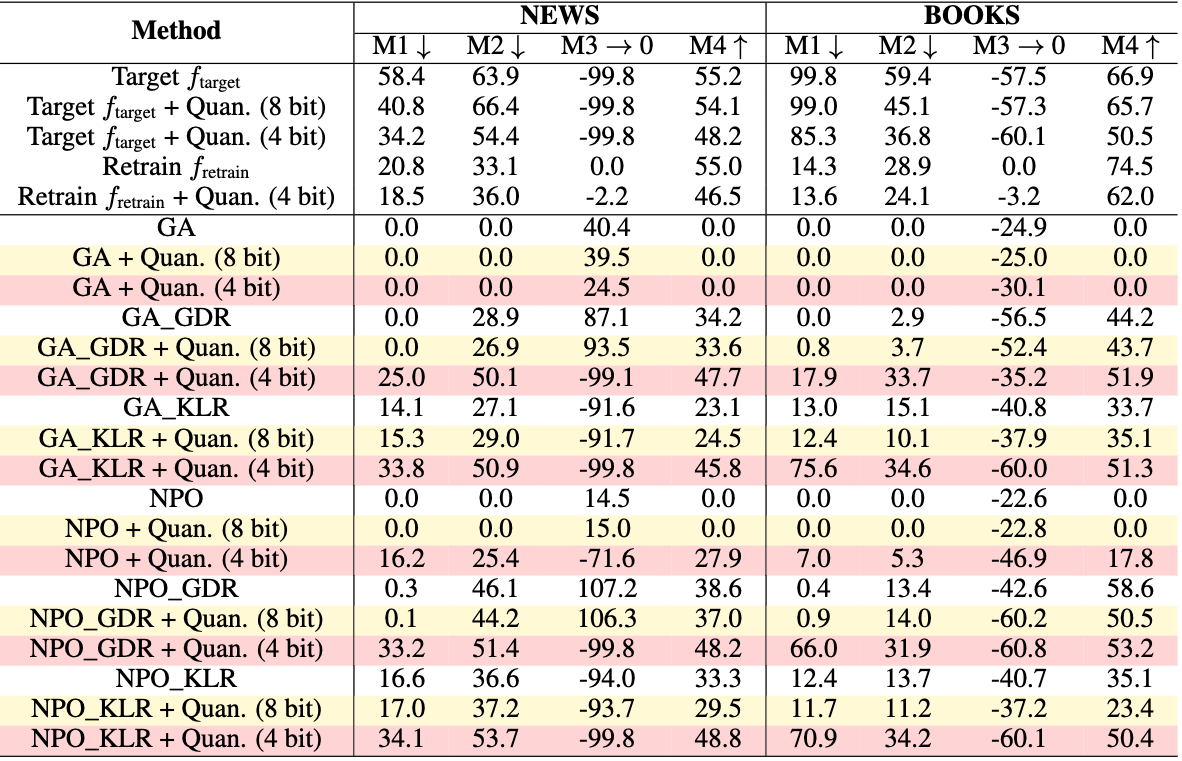
Implication: Fake unlearning makes the model fragile to structural changes, such as quantization or pruning, which can inadvertently recover forgotten knowledge.
Consequence 4: Reduction in Model Capacity
By hiding the goods instead of removing them, the boy reduces the usable space in the apartment. Similarly, instead of freeing up capacity, fake unlearning effectively diminishes it.
In the context of LLMs, when unlearning is performed on a pretrained model, we naturally believe that the capacity of the model would increase, as the knowledge decreases in the knowledge bank. However, if fake unlearning happens, its behavior reduces the model’s ability to learn new tasks, undermining its effectiveness in applications like continual learning.
Implication: Fake unlearning diminishes the model’s effective capacity instead of freeing them up, limiting its potential for long-term adaptability.
Key Takeaway
Fake unlearning undermines the fundamental goals of machine unlearning. By merely hiding knowledge rather than removing it, the model remains vulnerable to attacks, structural changes, and capacity limitations. For machine unlearning to be truly effective, robust and authentic methods must be developed to address these vulnerabilities.
Pitfall 2: Over-Relying on the Proposed Forget Dataset
Machine unlearning often hinges on a pre-defined forget dataset, which contains data identified as problematic—whether due to copyright issues, harmful knowledge, or ethical concerns. While this dataset provides a clear target for unlearning, the question remains: is directly using the forget set always the optimal solution?
This approach, though straightforward, can lead to severe consequences, undermining the efficacy and utility of unlearning efforts. Below, we delve into two significant issues.
Consequence 1: Unnecessary Unlearning of Poorly Grasped Knowledge
Not all knowledge in the forget set is equally represented in the pretrained model. In many cases, the model may not have fully grasped certain samples from the forget dataset. Despite this, current practices assume that every sample in the forget set must be unlearned, leading to inefficiencies.
Unlearning poorly grasped knowledge can be counterproductive. If the model exhibits low confidence in predicting certain forget set samples, their impact on the model’s behavior is likely negligible. Treating all forget set samples equally wastes resources and may unnecessarily degrade the model’s overall utility.
The figure below illustrates this issue. Our preliminary study reveals that the pretrained Zephyr-7B model does not grasp all samples in the WMDP 7 forget set equally. Regions with a low Min-K=20% score (marked in orange) indicate data that are poorly learned by the model. This suggests that unlearning these samples may lead to an unnecessary utility drop without meaningful gains in unlearning effectiveness.
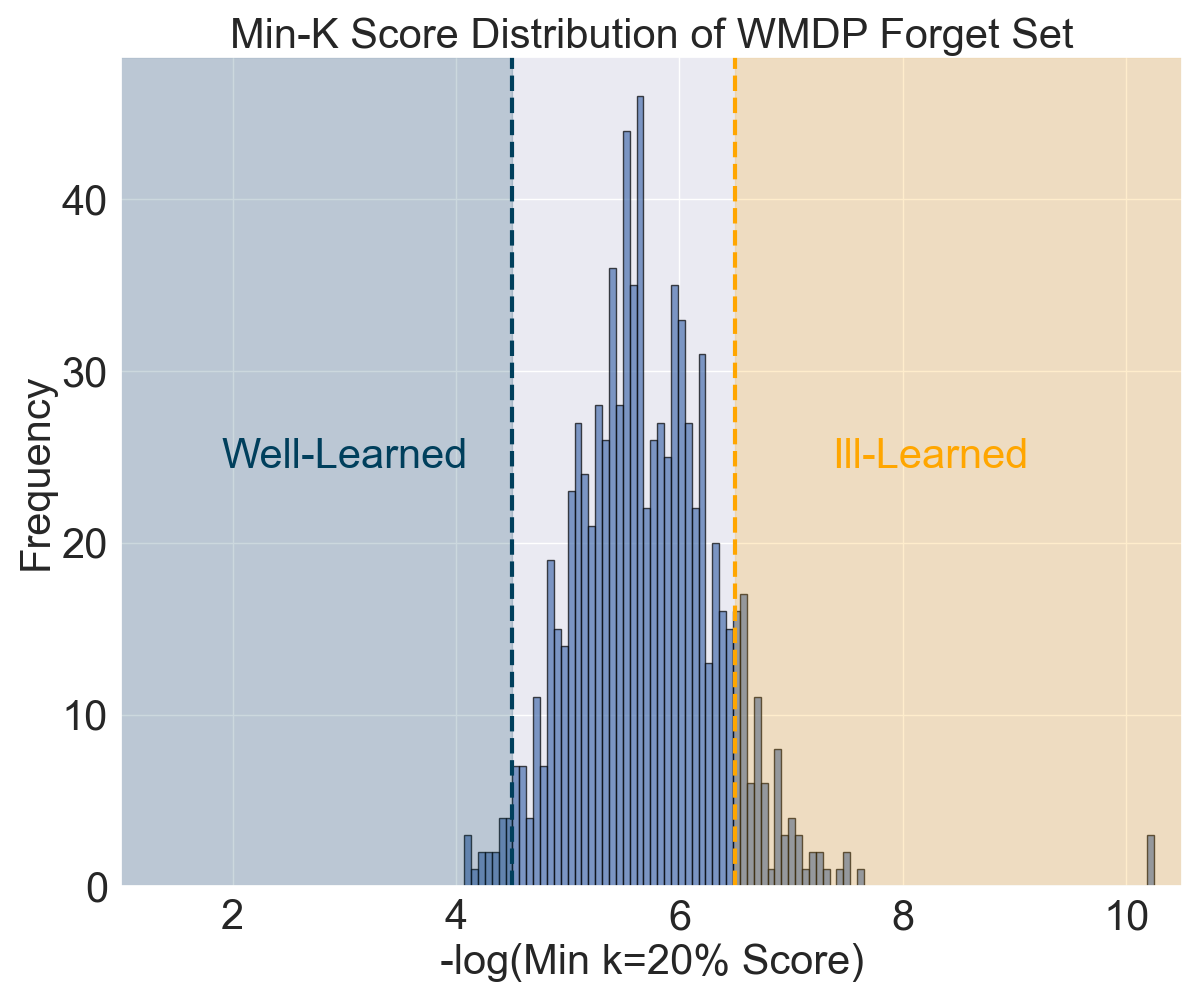
To address this, we explored a very straightforward selective unlearning approach by omitting forget set samples based on their prediction confidence. The figure below demonstrates that unlearning effectiveness and retainability remain nearly the same when approximately 10%–20% of low-confidence samples are excluded. Notably, removing around 30% of these samples achieves a better forgetting-retaining tradeoff, as shown by the fitted curve nearer to the top-right corner. This represents a win-win scenario: reducing data samples in the forget set not only improves the tradeoff but also boosts unlearning efficiency.
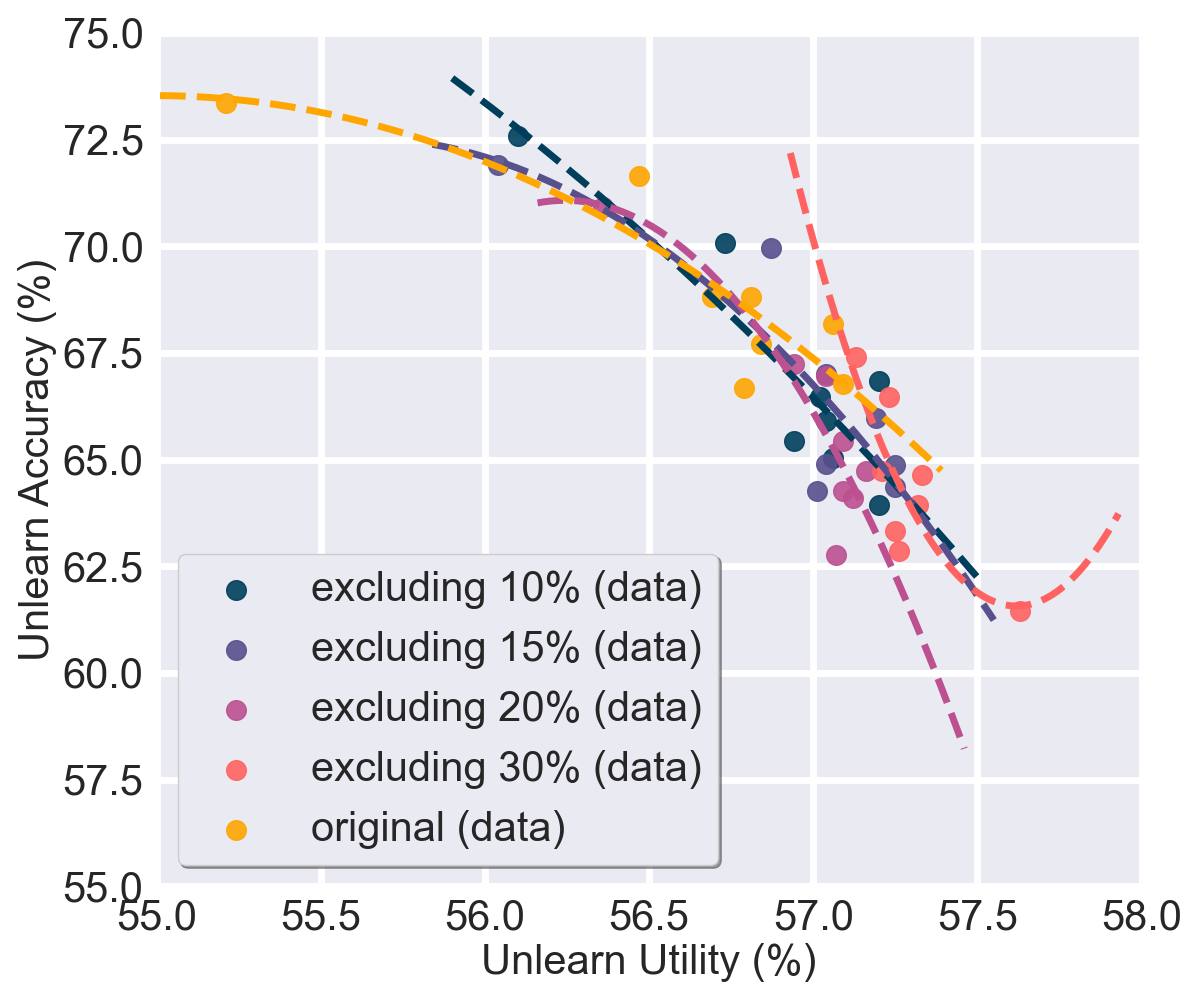
Implication: A selective approach—targeting only well-grasped knowledge in the forget set—leads to more effective and efficient unlearning, avoiding unnecessary utility loss.
Consequence 2: Neglecting an Unlearning Curriculum
When children learn new concepts, they begin with simpler ideas and gradually progress to more complex ones. This approach, known as a curriculum, allows for efficient and effective learning. Similarly, in the context of machine unlearning, adopting a curriculum-based approach could significantly enhance the process. However, this strategy has been largely overlooked.
The Current Problem
Existing unlearning methodologies treat all forget set samples equally. They apply uniform unlearning schedules and hyperparameters, failing to account for the varying levels of “unlearning difficulty” inherent in different samples. This lack of differentiation reduces the overall efficiency and effectiveness of the unlearning process.
A Possible Solution: Introducing an Unlearning Curriculum
A curriculum-based strategy prioritizes the removal of well-grasped knowledge (samples with high prediction confidence) before addressing less well-grasped knowledge (low prediction confidence). This incremental approach aligns with the model’s internal state and optimizes the unlearning process. In our experiments:
- We defined unlearning difficulty based on the model’s prediction confidence for forget set samples.
- We designed an unlearning curriculum that starts with well-grasped knowledge and progressively moves to less well-grasped knowledge.
- This approach achieved superior unlearning performance while maintaining overall model utility.
Implication: Incorporating an unlearning curriculum improves both the efficiency and effectiveness of the process, enabling a more tailored and impactful approach to model refinement.
Key Takeaway
Over-relying on predefined forget datasets can lead to unnecessary unlearning of poorly grasped knowledge and inefficiencies in the process. By adopting selective unlearning strategies and curriculum-based approaches, it is possible to improve unlearning effectiveness while preserving model utility and avoiding unnecessary degradation.
Pitfall 3: Overlooking the Broader Side Effects of Machine Unlearning
When evaluating the impact of machine unlearning, researchers often focus solely on the utility of the unlearned model for general knowledge-based datasets. While this is an essential metric, it provides an incomplete picture. Machine unlearning can have broader, often overlooked side effects, significantly affecting the model’s emergent abilities10, reasoning skills11, and hallucination tendencies12.
Consequence 1: Impairment of Emergent Abilities and Reasoning
Emergent abilities10 refer to the complex capabilities that arise as a result of scaling LLMs, such as in-context learning, augmented prompting, and reasoning. These abilities are widely regarded as critical characteristics of LLMs, enabling tasks like multi-step reasoning, contextual understanding, and advanced problem-solving. However, their vulnerability to unlearning side effects has been largely overlooked in evaluations.
Machine unlearning can disrupt these advanced abilities, especially when reasoning or other emergent skills rely on entangled knowledge connected to the forget set. Our preliminary study highlights this disruption by evaluating the original Zephyr-7B-Beta model and its unlearned version (using the NPO algorithm) on the WMDP dataset across tasks that represent emergent abilities. These include:
- Reasoning/In-context learning tasks: Assessed through MMLU (5-shot)13 and TruthfulQA14, which require multi-step inference, contextual understanding, and distinguishing truth from plausible-sounding falsehoods.
- Augmented prompting tasks: Evaluated through GPQA (0-shot chain-of-thought)16 and IFEval (0-shot)16, which test the model’s ability to generate coherent and logical responses based on extended prompts.
The results, summarized in the table below, reveal significant degradation in emergent abilities after unlearning:
| Model | MMLU (5-Shot) | Truthful QA | GPQA 0-shot CoT | IFEval 0-shot |
|---|---|---|---|---|
| Original | 59.82% | 38.80% | 11.83% | 54.39% |
| Unlearned | 57.25% | 34.27% | 5.36% | 27.94% |
The unlearned model consistently underperformed across all tasks, with particularly severe impacts on augmented prompting tasks like GPQA and IFEval. Reasoning tasks, while somewhat less affected, still showed a noticeable decline, underscoring the interconnected nature of these abilities.
Implication: The interconnected nature of knowledge in LLMs means that unlearning targeted data can unintentionally disrupt critical emergent abilities, including reasoning and advanced prompting. This underscores the need for careful evaluation and mitigation strategies to preserve these essential capabilities.
Consequence 2: Increased Hallucinations
Hallucinations, where the model generates incorrect or nonsensical information, are a persistent challenge in LLMs. Machine unlearning, by altering the model’s learned representations, can exacerbate this issue, destabilizing the model’s behavior and increasing the frequency of hallucinations.
To investigate this concern, we conducted a preliminary study using the Zephyr-7B-Beta model and evaluated its hallucination rate before and after unlearning on the Truthful QA dataset. Unlearning was performed with the NPO method on the WMDP dataset. Before unlearning, the model achieved an accuracy rate of 38.80%. After unlearning, the accuracy dropped to 34.27%, indicating an increase in factual inaccuracies in general knowledge by over 4%.
Implication: Poorly implemented unlearning strategies can destabilize the model, leading to more frequent and severe hallucinations. This highlights the importance of evaluating unlearning methods beyond traditional utility metrics to address their impact on model reliability.
Key Takeaway
Overlooking the broader side effects of machine unlearning can significantly impair a model’s emergent abilities and reasoning skills, while also increasing hallucination rates. Since knowledge in LLMs is highly interconnected, unlearning targeted data may unintentionally disrupt critical capabilities. To preserve model utility and reliability, unlearning strategies must carefully evaluate and mitigate these unintended consequences.
Conclusion
Machine unlearning holds immense potential to ensure the ethical and effective deployment of foundation models, yet its current methodologies face significant challenges. We have highlighted three critical pitfalls: the prevalence of fake unlearning, over-reliance on the forget dataset, and the neglect of broader side effects. Fake unlearning undermines robustness and reduces model capacity, while naive reliance on forget datasets leads to unnecessary unlearning and ignores the benefits of curriculum-based approaches. Additionally, unlearning can impair emergent abilities, reasoning skills, and hallucination tendencies if its broader effects are not carefully evaluated.
Addressing these pitfalls requires a paradigm shift in the design and evaluation of machine unlearning techniques. By incorporating selective and curriculum-based approaches, alongside comprehensive assessments of emergent and reasoning abilities, researchers can build more reliable and adaptive models. This blog aims to inspire the community to explore these overlooked aspects, paving the way for machine unlearning to become a cornerstone of trustworthy and efficient AI systems.
References
[0] Aliza Chasan. ** U.S. Tesla Cybertruck bomber used ChatGPT to plan Las Vegas attack, Police Say*, 2024. Available: https://www.cbsnews.com/news/las-vegas-cybertruck-explosion-fire-chatgpt-plan/
[1] M. M. Grynbaum and R. Mac. The Times sues OpenAI and Microsoft over A.I. Use of Copyrighted Work. The New York Times, 2023. Available: https://www.nytimes.com/2023/12/27/business/media/new-york-times-open-ai-microsoft-lawsuit.html
[2] V. Turk. How AI Reduces the World to Stereotypes. Rest of World, 2023. Available: https://restofworld.org/2023/ai-image-stereotypes/?utm_source=pocket-newtab-en-us
[3] J. Łucki, B. Wei, Y. Huang, P. Henderson, F. Tramèr, and J. Rando. An adversarial perspective on machine unlearning for ai safety. arXiv preprint arXiv:2409.18025, 2024.
[4] Y. Zhang, Y. Zhang, Y. Yao, J. Jia, J. Liu, X. Liu, and S. Liu. Unlearncanvas: A stylized image dataset to benchmark machine unlearning for diffusion models. arXiv preprint arXiv:2402.11846, 2024.
[5] A. Zou, Z. Wang, J. Z. Kolter, and M. Fredrikson. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023.
[6] Z. Zhang, F. Wang, X. Li, Z. Wu, X. Tang, H. Liu, Q. He, W. Yin, and S. Wang. Does your LLM truly unlearn? An embarrassingly simple approach to recover unlearned knowledge. arXiv preprint arXiv:2410.16454, 2024.
[7] N. Li, A. Pan, A. Gopal, S. Yue, D. Berrios, A. Gatti, J. D. Li, A.-K. Dombrowski, S. Goel, L. Phan, et al. The wmdp benchmark: Measuring and reducing malicious use with unlearning. arXiv preprint arXiv:2403.03218, 2024.
[8] J. Zhang, J. Sun, E. Yeats, Y. Ouyang, M. Kuo, J. Zhang, H. F. Yang, and H. Li. Min-k%++: Improved baseline for detecting pre-training data from large language models. arXiv preprint arXiv:2404.02936, 2024.
[9] L. Tunstall, E. Beeching, N. Lambert, N. Rajani, K. Rasul, Y. Belkada, S. Huang, L. von Werra, C. Fourrier, N. Habib, et al. Zephyr: Direct distillation of lm alignment. arXiv preprint arXiv:2310.16944, 2023.
[10] J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler, et al. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682, 2022.
[11] J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35: 24824–24837, 2022.
[12] Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y. Xu, E. Ishii, Y. J. Bang, A. Madotto, and P. Fung. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38, 2023.
[13] D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
[14] S. Lin, J. Hilton, and O. Evans. Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958, 2021.
[15] D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y. Pang, J. Dirani, J. Michael, and S. R. Bowman. Gpqa: A graduate-level google-proof q\&a benchmark. arXiv preprint arXiv:2311.12022, 2023.
[16] J. Zhou, T. Lu, S. Mishra, S. Brahma, S. Basu, Y. Luan, D. Zhou, L. Hou, et al. Instruction-following evaluation for large language models. arXiv preprint arXiv:2311.07911, 2023. ```
机器反学习(Machine unlearning)已经成为从大模型中移除有害、带偏见或受版权保护的信息的重要技术,为在人工智能系统中提升可信度和合规性提供了一条可行途径。本文探讨了当前实现中被忽视的关键陷阱,其中包括“虚假的遗忘”(fake unlearning)这一概念——即知识并未真正被移除,而是被隐藏起来,从而带来如越狱攻击(jailbreak attack)、连续反学习中的不稳定性以及模型容量衰减等漏洞。我们还讨论了仅依赖预先定义的遗忘数据集(forget datasets)的局限性,这种方式可能导致不必要的反学习和错失基于课程式优化(curriculum-based optimization)的机会。最后,我们探讨了反学习带来的更广泛副作用,包括对涌现能力(emergent abilities)、推理技能以及幻觉(hallucination)率的不利影响。通过解决这些挑战,我们提出了若干策略,以构建稳健、高效且全面的反学习方法,使其与可信AI的目标保持一致。
机器反学习:在大模型中对“补丁”的需求
想象你正在开发一个软件应用。当用户遇到导致不良行为的“bug”时,你会发布一个补丁(patch)来修复它们。随着时间推移,这些补丁不断演化,形成了软件的新版本,既保持了功能性,又修复了特定缺陷。这种迭代改进过程对软件开发至关重要。
现在,将这个概念应用到大模型(foundation models)上,如大型语言模型(LLMs)和扩散模型(DMs)。这些模型常被视为现代AI的基础构件,但并非不存在“bug”。在这里,“bug”表现为有害的行为、隐私泄露或偏见输出。然而,与软件不同的是,给这些大模型打“补丁”远比修复软件要复杂得多。
这正是机器反学习发挥重要作用的地方。可以将机器反学习视作给大模型的“补丁”:它会在保持整体能力的同时,对预训练模型中特定知识或行为进行精确移除。这样就能在不重新从零训练的情况下对模型进行高效调试,从而节省时间和计算资源。当看到如下现实场景时,反学习的必要性就更加凸显:
1. 生成有害内容
大型语言模型在不当提示下可能产生有害输出。例如,如果生成了关于“如何培育病毒”的建议,后果可能非常严重。在 2024 年特斯拉 CyberTruck 爆炸案嫌疑人曾使用 ChatGPT 自制炸弹0。类似地,文本到图像的扩散模型也可能在已设置的安全机制下无意中生成不适宜的内容(如裸露画面)。
2. 隐私和版权违规
大模型通常使用来自互联网的大规模抓取数据进行训练,其中可能包含受版权保护的材料。例如,《纽约时报》就因其作品被违规用于训练数据集而起诉多家主要AI开发商。机器反学习为此类伦理和法律风险提供了缓解机制,能够将受版权保护数据的影响从模型中剔除。
3. 偏见和刻板印象
AI 模型常常会复制其训练数据中存在的社会偏见。例如,一个扩散模型在输入提示“一个墨西哥人”时,可能生成带有刻板印象的图像,如戴着墨西哥毡帽的老年男性。这些偏见会侵蚀人们对AI系统的信任,并强化有害的刻板印象。
机器反学习的数学框架
针对扩散模型(DMs)和大型语言模型(LLMs),我们可以对机器反学习的过程进行数学公式化。下面简要介绍关键目标和公式:
1. 扩散模型
在扩散模型中,反学习的目的是在保留图像质量的同时,防止生成有害或不需要的内容。其优化问题可表示为:
\[\min_{\Delta \theta} L_{\text{unlearn}}^{\text{DM}}(\theta_u) = \mathbb{E}_{(x, c) \sim D_f, t, \epsilon \sim \mathcal{N}(0, 1), c' \neq c} \left[\| \epsilon_{\theta_u}(x_t | c') - \epsilon_{\theta_u}(x_t | c) \|_2^2 \right] + \beta \ell_{\text{MSE}}(\theta_u; D_r),\]其中:
- \(\epsilon_{\theta}\):噪声估计器(noise estimator)。
- \(c\):有害概念(例如裸露)。
- \(c'\):不同且无关的概念。
- \(\ell_{\text{MSE}}\):图像重建的均方误差损失(mean squared error loss)。
- \(D_f\) 和 \(D_r\):分别表示需要忘却的数据集(forgetting dataset)和需要保留的数据集(retaining dataset)。
- \(\beta\):用于权衡反学习和保持目标的正则化参数。
2. 大型语言模型
对 LLM 而言,目标是在消除不良内容(如有毒或受版权保护的文本)的同时,保留其通用语言能力。优化过程可定义为:
\[\min_{\theta} \mathbb{E}_{(x, y_f) \in D_f} \left[\ell(y_f | x; \theta) \right] + \lambda \mathbb{E}_{(x, y) \in D_r} \left[\ell(y | x; \theta)\right],\]其中:
- \(\ell(\cdot)\):模型预测的损失函数。
- \(y_f\):反学习后期望得到的响应。
- \(D_f\) 和 \(D_r\):需要忘却和需要保留的数据集。
- \(\lambda\):正则化参数。
权衡移除与保留
机器反学习并非只关乎移除有问题的影响;它还强调有选择性地移除,以尽量降低重训成本并保留模型效用。能高效移除不良数据影响又能保留无关能力,这正是反学习作为大模型调优的一种高效且可扩展的途径之所在。
陷阱一:虚假的遗忘(Fake Unlearning)问题
母子故事的比喻
可以将机器反学习比作一位妈妈让儿子把一箱不需要的物品从公寓里搬走。在这个比喻中:
- 物品代表需要被遗忘的知识。
- 公寓代表大模型。
儿子有两种方式可以执行任务:
- 真实的反学习:真的把那箱东西搬出公寓。
- 虚假的遗忘:将箱子藏在公寓的某个角落或储藏室里。对外看来箱子似乎被移走了,但实质上还隐藏在室内。
虚假的遗忘也许能制造短暂的有效假象,却会带来严重的问题,严重削弱模型的可靠性和性能。以下将详细阐述虚假的遗忘的具体后果,并用类比进行说明。
后果 1:易受对抗性/越狱式攻击
如果妈妈检查公寓的每个角落,最终她还是会在储物间找到被儿子藏起来的箱子。类似地,通过优化的方法进行的对抗性或越狱式攻击可以像一个细心的“搜查官”那样,遍历模型中所有角落,试图恢复那些本应被遗忘的知识。这种现象在大型语言模型3和扩散模型4中都有观测到。
如下图所示,在面对普通的、非对抗性提示时,反学习模型可能表现出较高的反学习有效性。然而,一旦遭遇对抗性攻击,所有最先进的反学习方法都可能无法阻止被遗忘的知识被找回,体现了虚假的遗忘的普遍性。
类似地,对于 LLM 的反学习,越狱式攻击也被证明能够成功诱使反学习后的模型生成似乎已经被遗忘的内容,其方法包括 GCG 攻击5等对抗性提示优化。下表中的结果说明了:
启示:虚假的遗忘无法为模型提供对抗攻击的稳固防护,遗忘知识仍能被挖掘并恢复。
后果 2:连续反学习中被遗忘知识的回流
假设妈妈多次让儿子搬走不同的物品,如果儿子不断将它们藏在同一个小储藏室里,储藏室迟早会装不下。等到东西满溢时,先前藏起来的箱子就会被挤回公寓。机器反学习中也会出现类似的情况,即在连续反学习(sequential unlearning)时,一次又一次的反学习请求会让之前隐藏的信息重新浮现,如下图所示。
在这种场景下,由于多个反学习操作积累了大量被隐藏的信息,早先遗忘的知识又会“卷土重来”。已有文献将此现象称为反学习回弹效应(unlearning rebound effect)。如同下表所示,随着更多的反学习请求被执行,许多扩散模型的反学习方法在之前的遗忘目标上出现了显著的遗忘准确度上升(表格中橙色标记部分)4。
启示:虚假的遗忘在连续反学习任务中会引发不稳定性,导致此前被遗忘的知识重新出现。
后果 3:在量化或剪枝操作下的脆弱性
想象公寓在翻新过程中变小,或者地震导致房屋结构轻微受损,那么储藏室也会随之缩小,以前藏起来的箱子就会“露馅”。对于虚假的遗忘而言,当对模型进行量化(quantization)或剪枝(pruning)等结构性改动时,也会重新暴露那些应该被遗忘的知识。
已有研究6表明,量化后的大部分模型都在遗忘指标上表现出显著下降,这说明结构性变化会破坏虚假的遗忘的稳定性,导致已被隐藏的知识再次被发现。下图显示了量化模型在反学习有效性方面的退化。
启示:虚假的遗忘导致模型在结构性变化(如量化或剪枝)时极度脆弱,会无意中恢复被隐藏的知识。
后果 4:模型容量的缩减
把东西藏起来并不释放公寓空间,就像阻塞了可用面积。类似地,虚假的遗忘并未真正释放模型的容量,反而在一定程度上挤占了其资源。
对LLM进行反学习时,我们原本希望随着知识量的减少,模型的容量应当增加。然而,如果反学习是“假的”,其过程反而降低了模型未来学习新任务的能力。这在持续学习(continual learning)等应用中会削弱模型的效用。
启示:虚假的遗忘实际上会削弱模型的有效容量,而非腾出空间,从而限制其长期适应能力。
关键结论
虚假的遗忘背离了机器反学习的初衷:它仅仅隐藏知识,却没有真正移除,导致模型仍然容易受到攻击和结构变化的影响,并削弱模型容量。若要实现真正有效的机器反学习,就必须开发稳健且真正去除知识的技术来应对这些漏洞。
陷阱二:过度依赖预先指定的“遗忘数据集”
机器反学习通常依赖一个预先定义的遗忘数据集(forget dataset),其中包含被鉴定为有问题(侵权、有害或道德上有争议)的数据。尽管这一数据集为反学习提供了明确的目标,但问题在于:直接使用这份数据集真的总是最优解吗?
这种直接方法虽然简单,却可能带来严重后果,破坏反学习的效果和实用性。以下我们来探讨其中两个主要问题。
后果 1:对尚未被模型充分掌握的知识进行不必要的反学习
遗忘数据集中的所有知识并不一定都被模型深入掌握。很多情况下,模型对于遗忘数据集中一些样本的掌握程度本就有限。然而,现有做法往往默认对数据集中的所有样本都执行反学习,造成资源浪费。
对于模型预测置信度很低的忘却数据样本,实际上对模型行为的影响很可能是微乎其微的。将这些尚未深入掌握的样本也纳入反学习进程,不仅无法显著提升反学习效果,反而浪费了计算资源,并潜在地降低了模型的整体效能。
下图阐明了这一问题:我们的初步研究发现,预训练的 Zephyr-7B 模型对于 WMDP 7 遗忘数据集并非所有样本都“深度理解”。图中橙色部分的 Min-K=20% 分数较高,表示模型对这些样本的掌握度较差。对这些未深入掌握的样本进行反学习,可能既不提升反学习效果,还会平白损耗模型效用。
我们尝试了一种非常简单的“选择性反学习”方法,即根据模型预测置信度,排除部分在遗忘数据集中掌握度不高的样本。下图表明,在排除约10%–20%低置信度样本后,反学习的有效性和保留性几乎没有受到影响。当排除的样本比例达到30%时,甚至获得了更好的遗忘-保留权衡(图中曲线更靠近右上角)。这是一种双赢的局面:减少低置信度样本不仅提高了反学习效率,还增强了整体反学习表现。
启示:只对模型真正掌握并会影响其行为的样本进行反学习,可以更高效且更有效地移除问题知识,同时避免不必要的模型效用损失。
后果 2:忽视反学习中的“课程式”方法
儿童在学习新知识时,通常会先从简单内容入手,然后逐步过渡到更复杂的知识点,这就是所谓的“课程学习(curriculum)”策略。在机器反学习领域,类似的课程式策略也有可能极大提高效率和效果,但目前却很少被采用。
当前问题
现有反学习方法一般把遗忘数据集视为同等重要,对所有样本采用统一的反学习调度和超参数设定,忽略了各个样本在“反学习难度”上的差异。这种一刀切的方法在效率和效果上都有所欠缺。
可能的解决方案:引入“反学习课程”
通过课程式策略,可以先移除模型已经深度掌握(高置信度)的知识,然后再逐步处理掌握度较低的知识。此种渐进式方法更能与模型内部状态契合,从而提升反学习的整体效率和效果。在我们的实验中:
- 用模型对忘却数据样本的预测置信度来定义反学习难度。
- 设计课程式反学习方案,从高置信度样本开始,逐步处理低置信度样本。
- 结果显示,这种策略在保持模型效用的同时,显著提升了反学习的表现。
启示:课程化的反学习方法能在效率和效果上双提升;通过更精准地安排反学习顺序,可以更好地优化模型改进的过程。
关键结论
过度依赖预先定义的遗忘数据集会导致针对尚未深入掌握知识的不必要反学习,并在整体流程中忽视了课程式方法的优势。通过采用选择性和课程式反学习策略,我们不仅可以提升反学习的效果,同时也能维持甚至增强模型效用,避免多余的损耗。
陷阱三:忽视机器反学习可能的更广泛的副作用
在评估机器反学习的影响时,研究人员往往只关注模型在常规知识数据集上的表现。然而,这只能呈现一个不完整的视角。机器反学习还会有更深层次的连带效应,可能显著影响模型的涌现能力(emergent abilities)10、推理能力11以及幻觉(hallucination)现象12等。
后果 1:对涌现能力和推理的损害
涌现能力10指的是随着LLM规模扩大而自然出现的复杂功能,如上下文学习(in-context learning)、提示增强(augmented prompting)和推理等。它们被普遍认为是大型语言模型的重要特性,支持多步推理、上下文理解和高级问题求解。但目前对它们在反学习中的脆弱性关注不足。
当模型的推理或其他涌现能力与需要被遗忘的数据存在联系时,反学习就可能破坏这些能力。我们的一项初步研究对比了原始的 Zephyr-7B-Beta 模型与其在 WMDP 数据集上使用 NPO 算法进行反学习后的版本,测试了若干代表涌现能力的任务:
- 推理/上下文学习任务:通过 MMLU (5-shot)13 和 TruthfulQA14 评估模型在多步推理、上下文理解以及辨别真伪信息上的能力。
- 增强提示任务:通过 GPQA (0-shot chain-of-thought)15 和 IFEval (0-shot)16,评估模型在扩展提示下生成连贯、合乎逻辑答案的能力。
下表展示了结果,说明反学习对涌现能力的负面影响十分明显:
| Model | MMLU (5-Shot) | Truthful QA | GPQA 0-shot CoT | IFEval 0-shot |
|---|---|---|---|---|
| Original | 59.82% | 38.80% | 11.83% | 54.39% |
| Unlearned | 57.25% | 34.27% | 5.36% | 27.94% |
可以看到,反学习后的模型在所有任务上表现均下降,尤其是类似 GPQA 和 IFEval 的增强提示任务跌幅更大。推理类任务虽然相对影响略小,但仍可见显著下降,这表明这些高级能力是相互关联的。
启示:模型内在知识的关联性意味着,当目标数据被遗忘时,也可能连带破坏模型的重要涌现能力,包括推理和高级提示技能。因此反学习评估需要更全面的指标,并针对这些副作用设计相应的防范措施。
后果 2:幻觉的加剧
幻觉是指模型输出不正确或荒谬信息的现象,一直是LLMs面临的挑战。由于反学习会改变模型的内部表示,一些粗糙的反学习手段可能会让模型更加不稳定,从而提高幻觉发生率。
我们对 Zephyr-7B-Beta 模型在执行 NPO 方法的反学习前后,测试了 TruthfulQA 数据集,以观察幻觉率的变化。反学习前,模型准确率为38.80%,而反学习后则降至34.27%,说明在一般性知识方面出现了约4%以上的错误增长。
启示:若反学习方法缺乏精细设计,会导致模型更容易产生幻觉,从而破坏其整体可靠性。这也提醒我们要扩展评估维度,不仅限于常规任务表现,更需关注幻觉率等可靠性指标。
关键结论
若忽视机器反学习的更广泛副作用,模型可能在涌现能力、推理技能以及幻觉率方面出现显著劣化。由于LLM内部知识具有高度关联性,移除针对性的目标数据可能会意外破坏关键能力。要想保留模型的实用性和可靠性,反学习方法必须在设计和评估时充分考虑并减轻这些潜在影响。
结论
机器反学习在确保大模型合乎伦理和高效应用方面具有巨大潜力,但现有方法仍面临重大挑战。本文重点讨论了三个关键陷阱:虚假的遗忘的普遍存在、对遗忘数据集的过度依赖以及对更广泛副作用的忽视。虚假的遗忘会削弱模型的稳健性并占用模型容量;简单依赖遗忘数据集会导致对尚未深入掌握知识的不必要反学习,也忽略了课程式方法带来的优势;此外,若忽视反学习的更广泛影响,模型的涌现能力、推理技能和幻觉率等关键指标都有可能恶化。
要应对这些陷阱,需要对机器反学习的设计和评估进行深层次的重构。我们倡导将选择性与课程式反学习相结合,并在评估时纳入对涌现能力和推理技能等指标的全面考量,从而开发出更可靠且具适应性的模型。希望本文能激发研究社区对这些被忽视问题的关注,为将机器反学习发展成为可信且高效的AI核心技术而共同努力。
References
[0] Aliza Chasan. ** U.S. Tesla Cybertruck bomber used ChatGPT to plan Las Vegas attack, Police Say*, 2024. Available: https://www.cbsnews.com/news/las-vegas-cybertruck-explosion-fire-chatgpt-plan/
[1] M. M. Grynbaum and R. Mac. The Times sues OpenAI and Microsoft over A.I. Use of Copyrighted Work. The New York Times, 2023. Available: https://www.nytimes.com/2023/12/27/business/media/new-york-times-open-ai-microsoft-lawsuit.html
[2] V. Turk. How AI Reduces the World to Stereotypes. Rest of World, 2023. Available: https://restofworld.org/2023/ai-image-stereotypes/?utm_source=pocket-newtab-en-us
[3] J. Łucki, B. Wei, Y. Huang, P. Henderson, F. Tramèr, and J. Rando. An adversarial perspective on machine unlearning for ai safety. arXiv preprint arXiv:2409.18025, 2024.
[4] Y. Zhang, Y. Zhang, Y. Yao, J. Jia, J. Liu, X. Liu, and S. Liu. Unlearncanvas: A stylized image dataset to benchmark machine unlearning for diffusion models. arXiv preprint arXiv:2402.11846, 2024.
[5] A. Zou, Z. Wang, J. Z. Kolter, and M. Fredrikson. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023.
[6] Z. Zhang, F. Wang, X. Li, Z. Wu, X. Tang, H. Liu, Q. He, W. Yin, and S. Wang. Does your LLM truly unlearn? An embarrassingly simple approach to recover unlearned knowledge. arXiv preprint arXiv:2410.16454, 2024.
[7] N. Li, A. Pan, A. Gopal, S. Yue, D. Berrios, A. Gatti, J. D. Li, A.-K. Dombrowski, S. Goel, L. Phan, et al. The wmdp benchmark: Measuring and reducing malicious use with unlearning. arXiv preprint arXiv:2403.03218, 2024.
[8] J. Zhang, J. Sun, E. Yeats, Y. Ouyang, M. Kuo, J. Zhang, H. F. Yang, and H. Li. Min-k%++: Improved baseline for detecting pre-training data from large language models. arXiv preprint arXiv:2404.02936, 2024.
[9] L. Tunstall, E. Beeching, N. Lambert, N. Rajani, K. Rasul, Y. Belkada, S. Huang, L. von Werra, C. Fourrier, N. Habib, et al. Zephyr: Direct distillation of lm alignment. arXiv preprint arXiv:2310.16944, 2023.
[10] J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler, et al. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682, 2022.
[11] J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35: 24824–24837, 2022.
[12] Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y. Xu, E. Ishii, Y. J. Bang, A. Madotto, and P. Fung. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38, 2023.
[13] D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
[14] S. Lin, J. Hilton, and O. Evans. Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958, 2021.
[15] D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y. Pang, J. Dirani, J. Michael, and S. R. Bowman. Gpqa: A graduate-level google-proof q\&a benchmark. arXiv preprint arXiv:2311.12022, 2023.
[16] J. Zhou, T. Lu, S. Mishra, S. Brahma, S. Basu, Y. Luan, D. Zhou, L. Hou, et al. Instruction-following evaluation for large language models. arXiv preprint arXiv:2311.07911, 2023.